浅谈内存泄漏
内存泄漏是什么,内存泄漏有那些现象发生,如何定位和排查。本文试图从三个方法来说明内存泄漏排查的手段,并说明其原理。
内存泄漏的现象
在实际工作中,我们可能会遇到下面这些情况
- 伴随着服务器中的后台任务持续地运行,系统中可用内存越来越少;
- 应用程序正在运行时忽然被
OOM kill掉了; - 进程看起来没有消耗多少内存,但是系统内存就是不够用了;
- ……
类似问题,很可能就是内存泄漏导致的。我们都知道,内存泄漏指的是内存被分配出去后一直没有被释放,导致这部分内存无法被再次使用,甚至更加严重的是,指向这块内存空间的指针都不存在了,进而再也无法访问这块内存空间。
应用程序的内存泄漏可能是堆内存(heap)的泄漏,也可能是内存映射区(Memory Mapping Region)的泄漏。这些不同类型的内存泄漏,它们的表现形式也是不一样的。那么什么是堆内存,什么是内存映射区,程序的内存模型又是怎样的呢,我们来一层一层的拨开迷雾。
内存布局
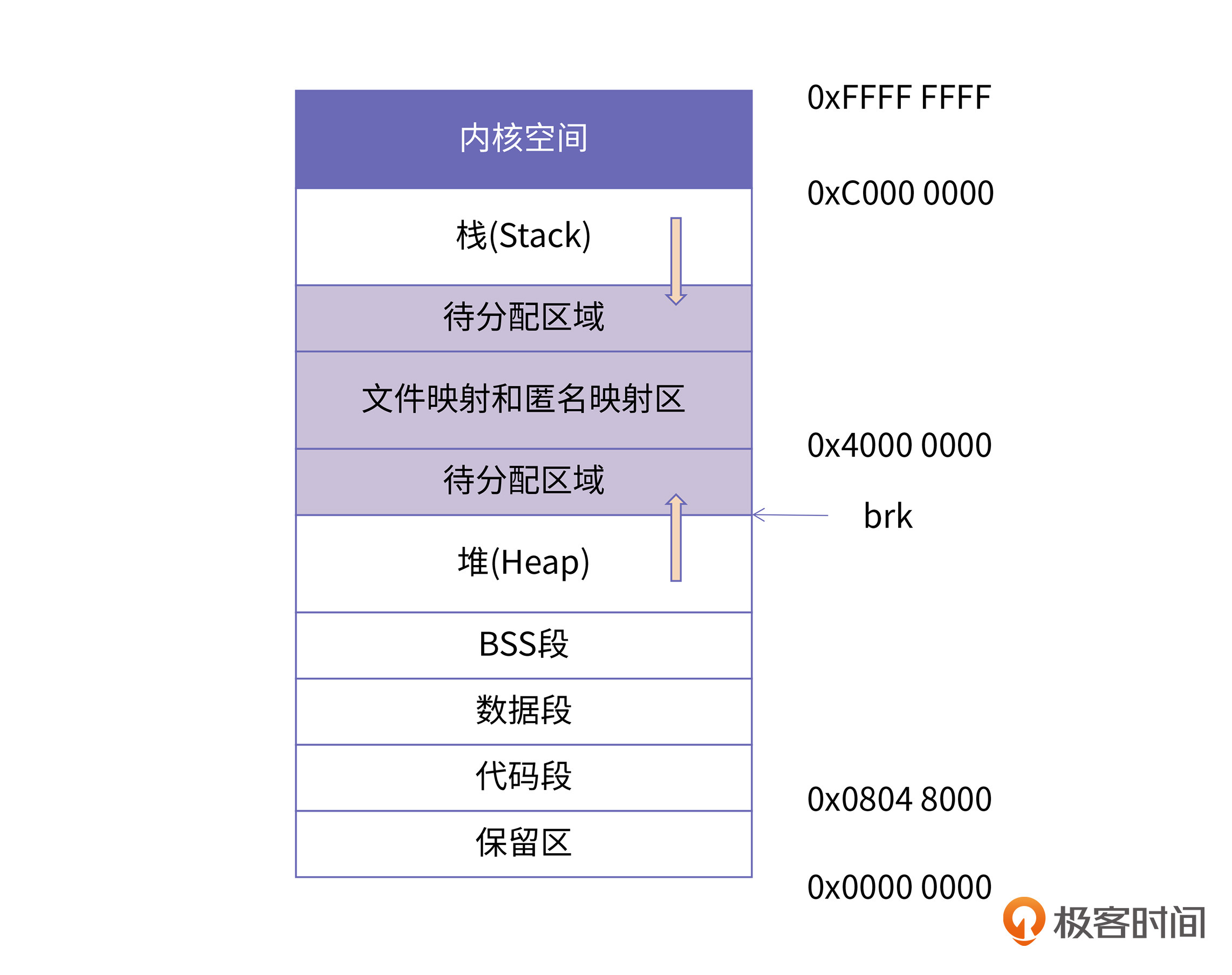
在32位机器上,每个进程都具有4GB的寻址能力。Linux系统会默认将高地址的1GB空间分配给内核,剩余的低3GB是用户可以使用的用户空间。下图是32位机器上Linux进程的一个典型的内存布局。
图片来自极客时间
从0地址开始的内存区域并不是直接就是代码段区域,而是一段不可访问的保留区。这是因为在大多数的系统里,我们认为比较小数值的地址不是一个合法地址。
- 代码段 .text,属性为只读
- 数据段 .data,属性为可读可写,保存有初始化的全局变量和初始化的静态变量
- BSS段 .bss,存放的是未初始化的全局变量和未初始化的静态变量,这里特别需要注意,未初始化的全局变量并不一定就是我们这里说的,直接保存在 BSS 段,后面我们会重点介绍。
- 堆 Heap,就是通过动态申请的内存,可以通过 malloc/new,或者系统调用 brk/sbrk/mmap 来申请的内存空间。这部分空间,由程序员手动申请和释放,也主要是内存泄漏可能发生的地方。堆的增长方向是从小到大。
- 文件映射和匿名映射区,一般就是动态库加载的内存区域
- 栈 stack,是由系统维护的内存空间,这部分的内存比较小,效率上也比堆要快很多。由系统进行申请和释放,不会发生内存泄漏,但是无限制使用栈空间,会导致栈溢出的错误发生。栈内存的增长方向与堆正好相反,从大到小。
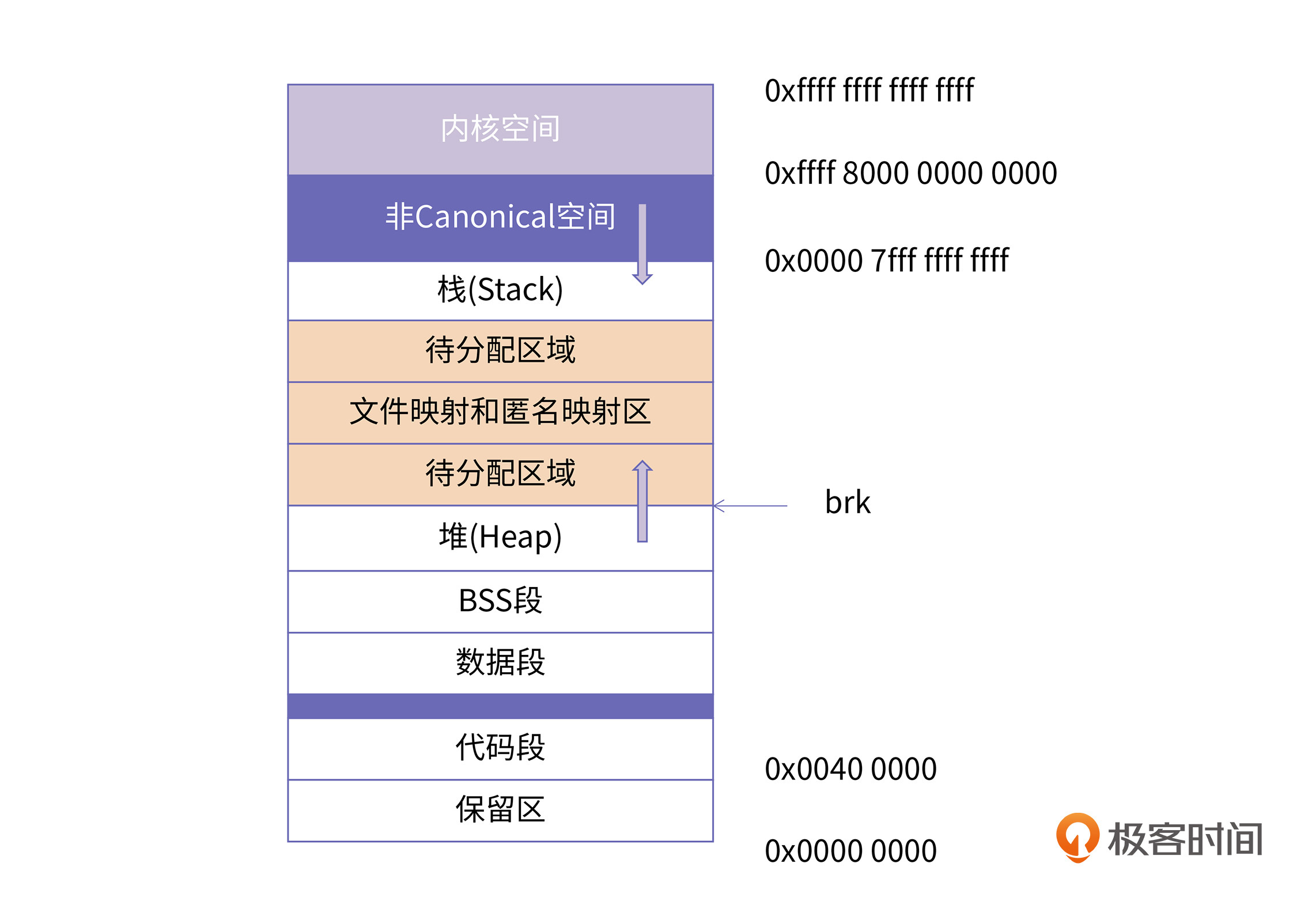
64位系统理论的寻址范围是2^64,也就是16EB。但是,依据 Intel 64 架构里定义的 canonical form 标准,64 位系统目前只支持低 48 位的总线寻址,在第 48-63 位填充全 0 或者全 1。也就是说,64为系统的寻址能力为 2^48,即 256 TB。而且根据canonical address的划分,地址空间天然地被分割成两个区间,分别是0x0 - 0x00007fffffffffff和0xffff800000000000 - 0xffffffffffffffff 两个 128 T 的空间。下面这张图展示了Intel 64机器上的Linux进程内存布局:
图片来自极客时间
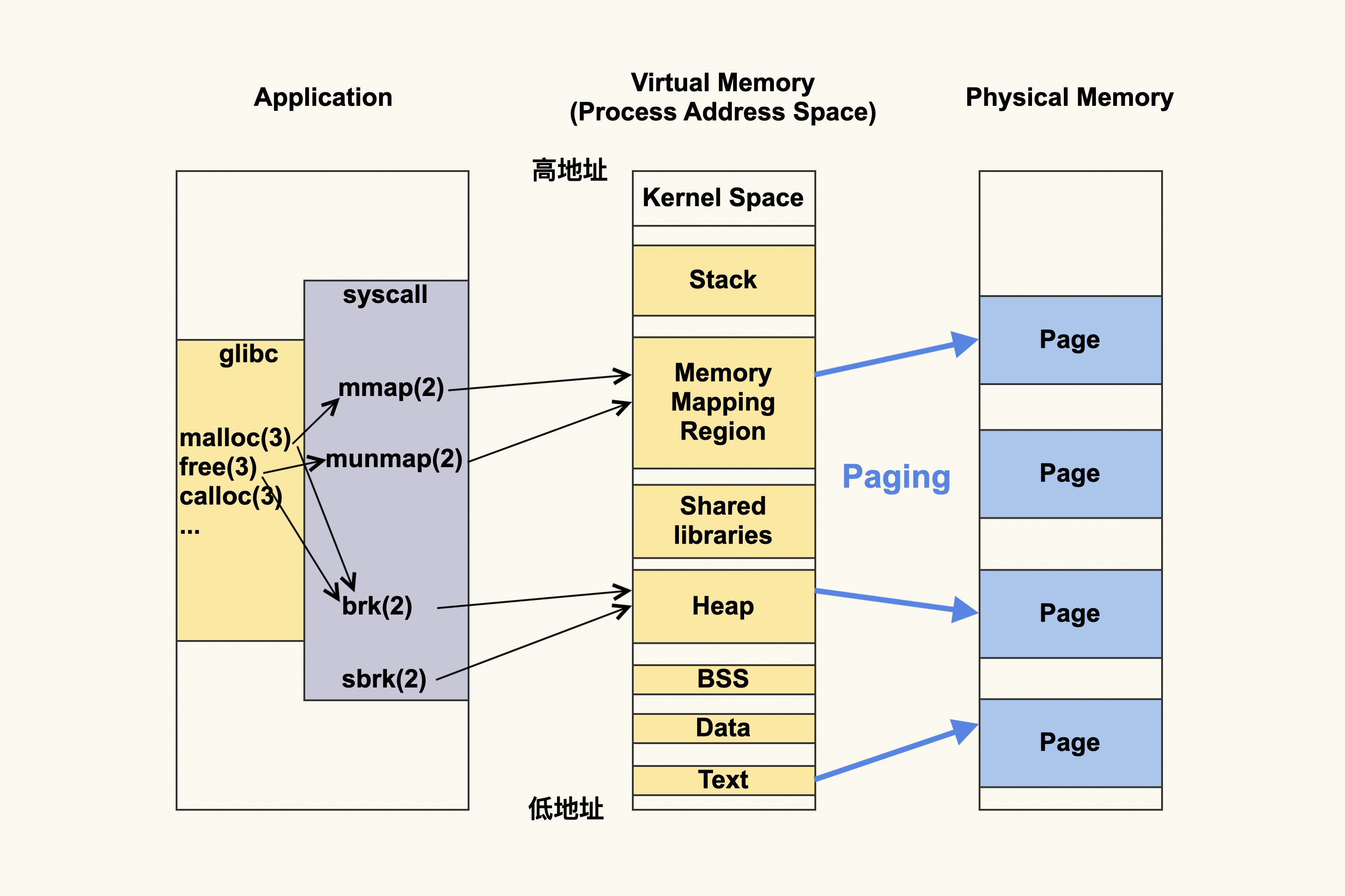
我们用一张图,来表示进程的地址空间。图的左侧是说进程可以通过什么方式来更改进程虚拟地址空间,而中间就是进程虚拟地址空间是如何划分的,右侧则是进程的虚拟地址空间所对应的物理内存或者说物理地址空间。
图片来自极客时间
应用程序首先会调用内存申请释放相关的函数,比如 glibc 提供的 malloc(3)、 free(3)、calloc(3) 等;或者是直接使用系统调用 mmap(2)、munmap(2)、 brk(2)、sbrk(2) 等。(括号里面的数字,表示的是 man page 的章节,一般 1 表示 shell command,2 表示系统调用,3 及以上都表示库函数)
我们用一张表格来简单汇总下这些不同的申请方式所对应的不同内存类型。

图片来自极客时间
进程运行所需要的内存类型有很多种,总的来说,这些内存类型可以从是不是文件映射,以及是不是私有内存这两个不同的维度来做区分,也就是可以划分为上面所列的四类内存。
- 私有匿名内存。进程的堆、栈,以及
mmap(MAP_ANON | MAP_PRIVATE)这种方式申请的内存都属于这种类型的内存。其中栈是由操作系统来进行管理的,应用程序无需关注它的申请和释放;堆和私有匿名映射则是由应用程序(程序员)来进行管理的,它们的申请和释放都是由应用程序来负责的,所以它们是容易产生内存泄漏的地方。 - 共享匿名内存。进程通过
mmap(MAP_ANON | MAP_SHARED)这种方式来申请的内存,比如说 tmpfs 和 shm。这个类型的内存也是由应用程序来进行管理的,所以也可能会发生内存泄漏。父子进程之间通过共享内存进行通讯,就是通过这种方式来实现的。 - 私有文件映射。进程通过
mmap(MAP_FILE | MAP_PRIVATE)这种方式来申请的内存,比如进程将共享库(Shared libraries)和可执行文件的代码段(Text Segment)映射到自己的地址空间就是通过这种方式。对于共享库和可执行文件的代码段的映射,这是通过操作系统来进行管理的,应用程序无需关注它们的申请和释放。而应用程序直接通过mmap(MAP_FILE | MAP_PRIVATE)来申请的内存则是需要应用程序自己来进行管理,这也是可能会发生内存泄漏的地方。 - 共享文件映射。进程通过
mmap(MAP_FILE | MAP_SHARED)这种方式来申请的内存,我们在上一个模块课程中讲到的File Page Cache就属于这类内存。这部分内存也需要应用程序来申请和释放,所以也存在内存泄漏的可能性。不同进程之间的通信,就可以通过共享文件映射的方式来实现。
NOTE: 进程虚拟地址空间是通过Paging(分页)这种方式来映射为物理内存的,进程调用malloc()或者mmap()来申请的内存都是虚拟内存,只有往这些内存中写入数据后(比如通过memset),才会真正地分配物理内存 。
引申:虚拟地址如何映射到物理地址空间?
那么,如果进程只是调用 malloc() 或者 mmap() 而不去写这些地址,即不去给它分配物理内存,是不是就不用担心内存泄漏了?答案是这依然需要关注内存泄露,因为这可能导致进程虚拟地址空间耗尽,即虚拟地址空间同样存在内存泄露的问题。
如何观察和判断是否发生了内存泄漏
我们常用来观察进程内存的工具,比如说pmap、ps、top等,都可以很好地来观察进程的内存。
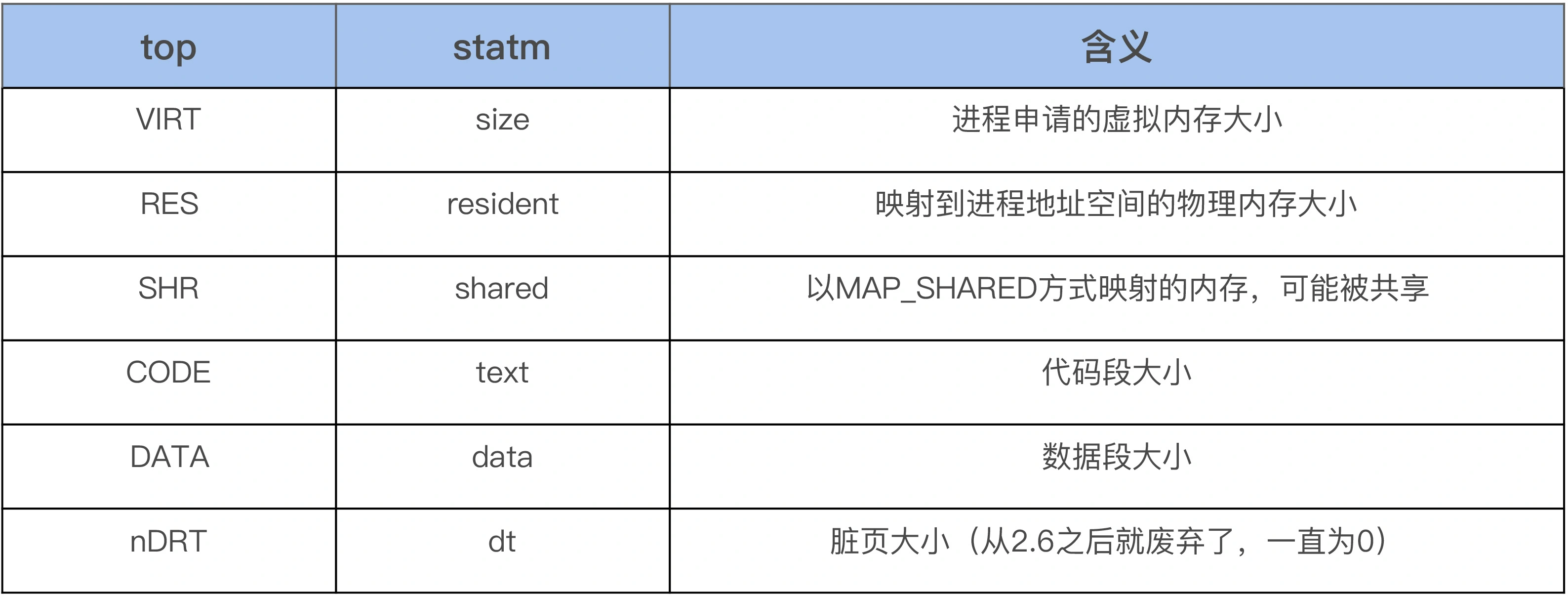
首先我们可以使用top来观察系统所有进程的内存使用概况,打开top后,然后按g再输入3,从而进入内存模式就可以了。在内存模式中,我们可以看到各个进程内存的%MEM、VIRT、RES、CODE、DATA、SHR、nMaj、nDRT,这些信息都是从 /proc/[pid]/statm 和 /proc/[pid]/stat 这个文件里面读取的。
图片来自极客时间
通过 pmap 我们能够清楚地观察一个进程的整个的地址空间,包括它们分配的物理内存大小,这非常有助于我们对进程的内存使用概况做一个大致的判断。比如说,如果地址空间中 [heap] 太大,那有可能是堆内存产生了泄漏;再比如说,如果进程地址空间包含太多的 vma(可以把 maps 中的每一行理解为一个 vma),那很可能是应用程序调用了很多mmap 而没有 munmap;再比如持续观察地址空间的变化,如果发现某些项在持续增长,那很可能是那里存在问题。
举个例子
假设我们现在有下面这个程序
#include <iostream>
#include <unistd.h>
#include <string.h>
int main(int argc, char *argv[]) {
while (1) {
int* a = new int[102400];
memset(a, 0, 102400);
sleep(1);
}
return 0;
}
很明显,这个程序存在内存泄漏问题。假设运行其中的程序我们并不知道,首先我们通过 top 进行观察(程序需要运行一段时间以后,才会更加明显)
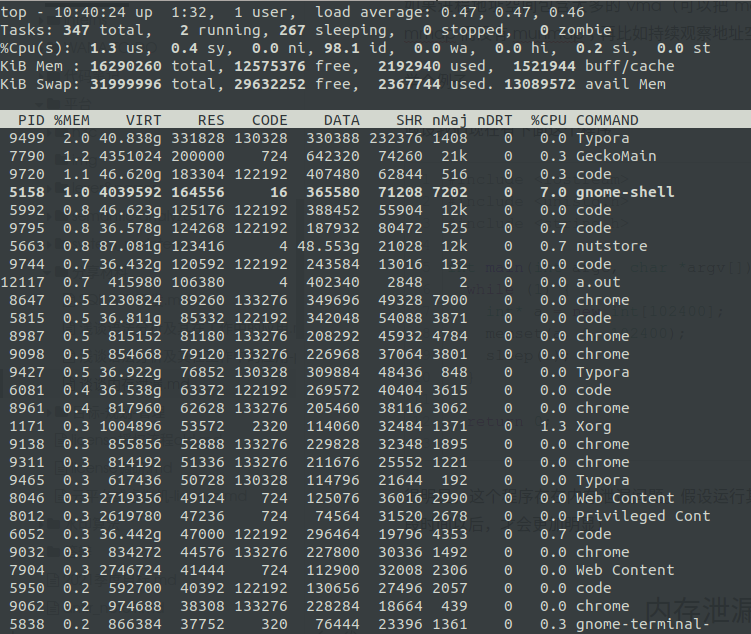
观察一段时间后发现,mem 中的 free 一直在不断变小,同时,有一个进程的虚拟内存VIRT 和物理内存 RSS 一直在变大,就是 pid 为 12117 的 a.out 进程。
我们通过 pidstat 对其进行持续观察,执行 一下命令
watch -d pidstat -r -p 12117
watch 命令用于监控 pidstat 命令的结果,-d 选项能够现实差异部分
pidstat 用于跟踪和分析进程的详细信息,-p attach 到某个具体的进程,-r 显示进程的内存使用情况。

每两秒,VSZ 也就是虚拟内存和 RSS 物理内存就会变化一次,而且是在持续的不断增大,可能这个程序就发生了内存泄漏。我们可以通过 top + c 的命令查看 a.out 的具体执行程序,可以通过 proc 文件系统来观察,
cat /proc/12117/maps
查看该进程的内存映射
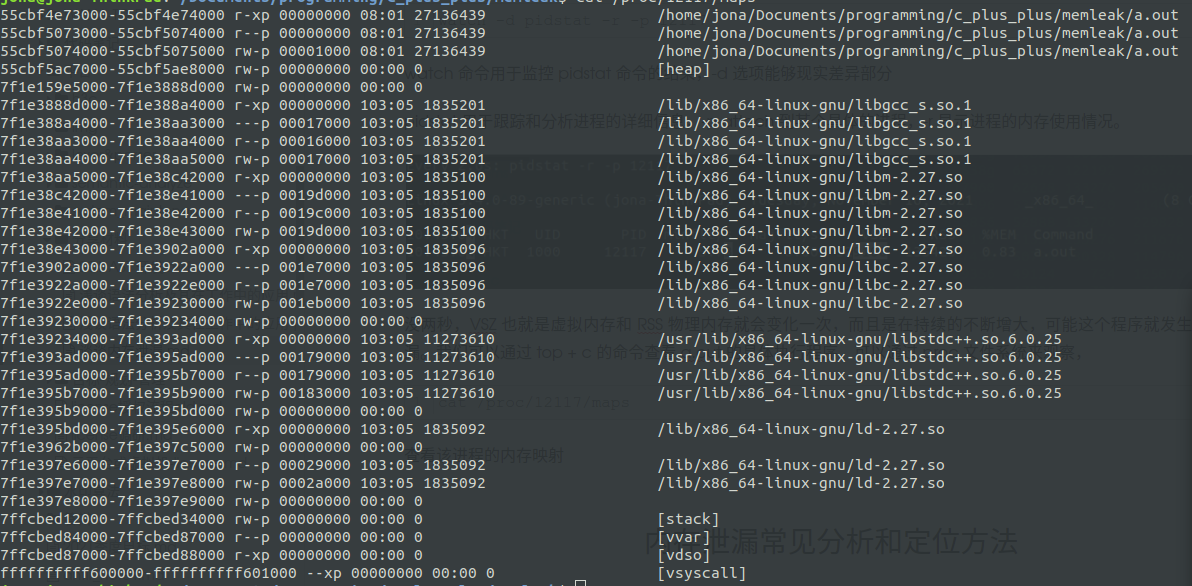
这个程序就是我们刚才执行的测试进程。
既然知道是哪个进程,下面就是对程序进行分析,定位程序中可能发生内存泄漏的地方了。
内存泄漏常见分析和定位方法
valgrind
valgrind 提供了一套工具集,可以用于程序调试和性能分析。
The Valgrind tool suite provides a number of debugging and profiling tools that help you make your programs faster and more correct. The most popular of these tools is called Memcheck. It can detect many memory-related errors that are common in C and C++ programs and that can lead to crashes and unpredictable behavior.
Memcheck 工具就是专门用来检测内存泄漏的。常见的使用参数如下
valgrind --trace-children=yes --leak-check=full --show-reachable=yes --track-origins=yes your_prog
用 valgrind 检测我们上述那个例子,
valgrind --trace-children=yes --leak-check=full --show-reachable=yes --track-origins=yes ./a.out
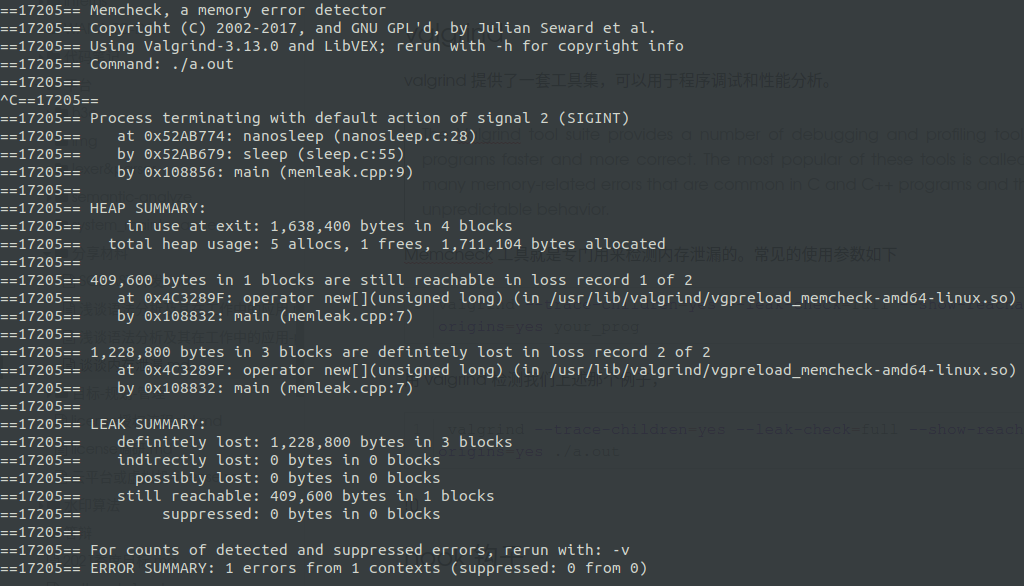
第一行信息就发现,valgrind 的 memcheck 工具检测到了一个错误 error。
- 17205 表示的执行的 a.out 这个进程的 pid
- HEAP SUMMARY 下面的每一个小段内容,就是 valgrind 检测出来的可能发生内存泄漏的区域,上述线索提示都是new 的堆没有释放导致,发生在 memleak.cp 的第 7 行。
继续往下看,我们来看一下 LEAK SUMMARY 中的错误提示
- definitely lost,表示肯定发生了内存泄漏,也就是必须要修复的错误
- indirectly lost,表示发生了内存泄漏,比如将堆内存的执行偏移到了堆的中间部位。这一部分可能是程序员的某种操作故意为之的。
- possible lost,可能发生了内存泄漏,需要关注。
其中只有 definitely lost 是一定发生了内存泄漏,必须要修复。(这种说法有点类似于编译器中的 MAY 和 MUST 算法,也就是说 valgrind 是 MAY 算法,肯定会报出所有可能出现的错误,这之间的错误信息有一些就是误报。但是又有 MUST 算法的意思在里面,也就是说,definitely lost 的错误,一旦检测到就一定发生了内存泄漏,但是可能还有其他的内存泄漏的错误没有检测出来,也就是可能出现漏报的情况。这里似乎两者兼而有之,也说明了这款工具的强大)。
valgrind 的 memcheck 还能检测未初始化的变量,提示信息为 “Conditional jump or move depends on uninitialised value(s)”,但是根据这些信息分析出其根因(root cause) 却是一件非常困难的事情,可以通过 --track-origins=yes 选项来获取额外的辅助信息来帮助定位问题。
原理
我们发现,valgrind 使用的时候,最后一个参数,实际是在执行我们的可执行文件,也就说,valgrind 类似于 attach 的方式一直在监控我们的进程。实际上,valgrind 实现了一个仿真器的模拟环境,模拟了一个CPU 环境。进程执行过程中的cpu寄存器,内存访问等数据都被valgrind捕获并在仿真环境中进行模拟,就相当于进程是在 valgrind 的仿真环境中进行执行,它的一举一动都被 valgrind 所监视。
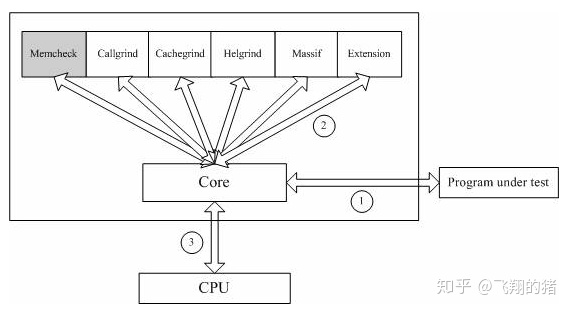
图片来自知乎
hook 钩子
通常在我们编写的代码中,可以将 jemalloc 这样的库链接到可执行文件,然后在程序中,使用 macro 的形式,对 malloc/free 进行重新定义,导向到 jemalloc 中内存申请或者释放的函数,那么程序中所有调用 malloc/free 的地方,都会使用新链接的库中定义的 malloc/free 方法,这样,我们就可以通过一些第三方性能分析工具,来收集和检测程序内存分配的情况。比如
#define malloc je_malloc
#define free je_free
利用这种思路,我们也可以对 new/delete 运算符进行重写,这样,程序在使用这些方法进行内存分配的时候,就使用我们自定义的方法来进行。这样,我们就可以在这些方法里面,添加一些额外的辅助信息,来帮助我们收集内存分配的一些信息,帮助我们定位内存问题。这就是 hook 的思路。
这里,我找到了吴咏炜老师写的一个辅助工具,仓库为 git@github.com:adah1972/nvwa.git,这个仓库里面有一个 debug_new 的小程序,可以用来辅助检测 new/delete 内存分配的问题。我们来看下这个代码的实现原理。
按照 hook 的思路,肯定需要对 new/delete 操作符进行重新定义,如下所示
void* operator new(size_t size)
{
return operator new(size,
static_cast<char*>(_DEBUG_NEW_CALLER_ADDRESS), 0);
}
void* operator new[](size_t size)
{
return operator new[](size,
static_cast<char*>(_DEBUG_NEW_CALLER_ADDRESS), 0);
}
void operator delete(void* ptr) noexcept
{
free_pointer(ptr, _DEBUG_NEW_CALLER_ADDRESS, alloc_is_not_array);
}
void operator delete[](void* ptr) noexcept
{
free_pointer(ptr, _DEBUG_NEW_CALLER_ADDRESS, alloc_is_array);
}
从上面可以看到,程序对 new/delete 进行了重新定义,分别调用了几个 new 的重载方法,在 delete 中调用了一个 free_pointer 方法。
/* Special allocation/deallocation functions in the global scope */
void* operator new(size_t size, const char* file, int line);
void* operator new[](size_t size, const char* file, int line);
void operator delete(void* ptr, const char* file, int line) noexcept;
void operator delete[](void* ptr, const char* file, int line) noexcept;
在 new 重载方法中,传入的参数为申请内存的大小,文件名和行号。也就是说,在 new 申请一块新的堆空间的同时,会将当前源文件以及申请内存的位置信息,即行号记录下来,与申请的这块空间保存在一起。这样,如果检测到发生内存泄漏,就可以直接通过这些信息,定位到内存泄漏的位置。
我们来看下保存这个信息的数据结构
struct new_ptr_list_t {
new_ptr_list_t* next; ///< Pointer to the next memory block
new_ptr_list_t* prev; ///< Pointer to the previous memory block
size_t size; ///< Size of the memory block
union {
char file[_DEBUG_NEW_FILENAME_LEN]; ///< File name of the caller
void* addr; ///< Address of the caller to \e new
};
uint32_t head_size; ///< Size of this struct, aligned
uint32_t line :31; ///< Line number of the caller; or \c 0
uint32_t is_array:1; ///< Non-zero iff <em>new[]</em> is used
#if _DEBUG_NEW_REMEMBER_STACK_TRACE
void** stacktrace; ///< Pointer to stack trace information
#endif
uint32_t magic; ///< Magic number for error detection
};
这是一个双链表,当我们通过 new 申请一块新的内存空间时,就将内存块的大小,文件名/申请的内存块的地址,行号,是否是数组等信息保存起来,加入到链表中。当程序结束时,遍历这个链表,如果链表为空,表示没有内存泄漏发生,如果链表非空,说明发生了内存泄漏,通过遍历链表中的节点,直接定位到内存泄漏发生的位置或者地址信息,帮助我们进行内存泄漏问题的定位。
具体来看下实现过程
void* operator new(size_t size, const char* file, int line)
{
void* ptr = alloc_mem(size, file, line, alloc_is_not_array);
if (ptr) {
return ptr;
} else {
throw std::bad_alloc();
}
}
在 new 的重载中,调用 alloc_mem 方法进行内存申请,如果申请失败,抛出 std::bad_alloc() 的异常。alloc_mem 就是实现内存申请的核心方法了。
/**
* Allocates memory and initializes control data.
*
* @param size size of the required memory block
* @param file null-terminated string of the file name
* @param line line number
* @param is_array flag indicating whether it is invoked by a
* <code>new[]</code> call
* @return pointer to the user-requested memory area;
* \c nullptr if memory allocation is not successful
*/
void* alloc_mem(size_t size, const char* file, int line,
is_array_t is_array,
size_t alignment = _DEBUG_NEW_ALIGNMENT)
{
...
uint32_t aligned_list_item_size = align(sizeof(new_ptr_list_t), alignment);
size_t s = size + aligned_list_item_size + _DEBUG_NEW_TAILCHECK;
auto ptr = static_cast<new_ptr_list_t*>(debug_new_alloc(s, alignment));
...
auto usr_ptr = reinterpret_cast<char*>(ptr) + aligned_list_item_size;
if (line) {
strncpy(ptr->file, file, _DEBUG_NEW_FILENAME_LEN - 1)
[_DEBUG_NEW_FILENAME_LEN - 1] = '\0';
} else {
ptr->addr = const_cast<char*>(file);
}
ptr->line = line;
...
ptr->is_array = is_array;
ptr->size = size;
ptr->head_size = aligned_list_item_size;
ptr->magic = DEBUG_NEW_MAGIC;
{
fast_mutex_autolock lock(new_ptr_lock);
ptr->prev = new_ptr_list.prev;
ptr->next = &new_ptr_list;
new_ptr_list.prev->next = ptr;
new_ptr_list.prev = ptr;
}
current_mem_alloc += size;
total_mem_alloc_cnt_accum++;
return usr_ptr;
上面我摘录了核心的代码部分。在申请内存时,首先根据 size 进行内存对齐,对齐后的空间,为 size + aligned_list_item_size,其中 aligned_list_item_size 保存的就是我们上面展示的链表节点信息。
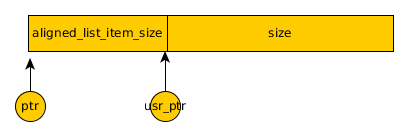
ptr 就是我们申请的这块堆内存的首地址指针,通过 ptr + aligned_list_item_size 偏移的方式,我们就得到了实际保存数据的指针 usr_ptr,我们在访问和操作的实际地址,就是从这里开始的。在 delete 释放时,也是同样的道理,首先根据 usr_ptr - aligned_list_item_size 的方式得到申请的内存块的实际地址,然后对该地址进行释放。
思考
我们在使用 jemalloc 进行链接时,是通过 macro 的方式,将 malloc 通过宏替换的方式,直接替换成了 jemalloc 中的内存申请和释放的 api。但是在上面 debug_new 这个小工具中,我们是直接对 new/delete 操作符进行的重写。
按照 c++ 的规则,函数重载,必须是参数类型,参数个数不同,仅函数返回值不同不构成函数重载。我们这里既不是虚函数重载,也没有改变 new/delete 的操作符的参数和参数个数,为什么可以直接进行重定义呢?
这就是我们接下来要讨论的一个重点,c/c++ 中强弱符号的引用。
强弱符号及其使用
参考 『程序员的自我修养 - 链接,装载与库』3.5.5节
在 c/c++ 中,编译器默认函数和初始化了的全局变量为强符号,而为初始化的全局变量为弱符号。强弱符号都是针对定义来说的,不是针对符号的引用。看下面这段代码
extern int ext;
int weak;
int strong = 1;
__attribute__((weak)) weak2 = 0;
strong 是初始化的全局变量,表示强符号,而 weak 和 weak2 都是弱符号。另外,ext 是一个外部引用的符号,既不是强符号,也不是弱符号,在链接器最终链接成可执行文件的时候,如果找不到外部符号 ext 的定义,会抛出 undefined 的错误。
规则:
- 不允许强符号被多次定义
- 如果一个符号在某个目标文件中是强符号,在其他目标文件中是弱符号,最终链接时,选择强符号
- 如果一个符号在所有目标文件中都是弱符号,选择占用空间最大的那一個弱符号(NOTE:现在编译器可能对此做了限定,测试结果发现,即使是弱符号,也必须都是相同类型,否则直接报错,这个下面会继续说明)
对于强符号的引用,在最终链接时,如果链接器没有找到该符号的定义,就会抛出符号未定义的错误。但是对于弱符号的引用,即使没有该符号的定义,编译器也不认为这是一个错误,能正常编译通过。
在 gcc 中,可以使用 __attribute__((weakref)) 这个扩展关键字来申明对一个外部函数的引用为弱引用。比如
__attribute__((weakref)) void foo();
int main(int argc, char* argv[]) {
if (foo) foo();
return 0;
}
如果此时我们有一个扩展模块,扩展模块中重新定义了 foo 这个接口函数时,将扩展模块与我们的程序链接,foo 就会使用扩展模块中的定义。这种方法使得程序的功能能够更加容易的裁剪和组合。
COMMON 符号
上面我们说过,程序中为初始化的全局变量,编译后会保存到 bss 段中,实际结果真是如此吗。我们来看下面这段代码
/// a.h
#ifndef __A_H__
#define __A_H__
#include <stdio.h>
int a;
int aaaaa = 0;
void show1();
#endif /* __A_H__ */
/// a.c
#include "a.h"
void show1() {
printf("sizeof a = %ld\n", sizeof a);
}
上面的代码,申明了一个未初始化的全局变量 a,同时申明和定义了一个全局函数 show1。通过 gcc 编译
gcc -g -c a.c
得到 a.o 中间文件,我们来分析一下这个文件里面的符号。
objdump -t a.o
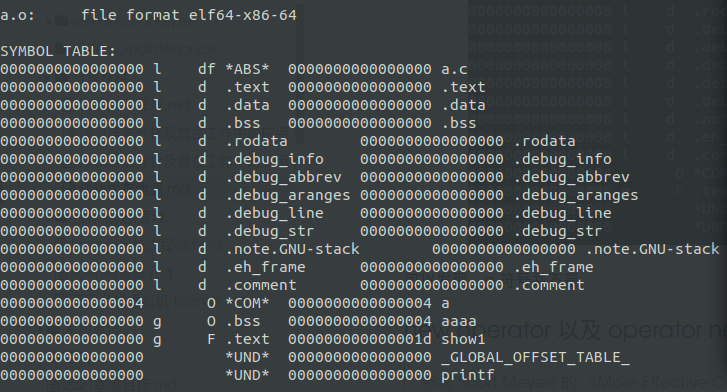
可以发现,aaaa 符号实在 .bss 段中,但是符号 a 并不是在 .bss 段中,而是一个 COMMON 的符号。
我发现很多说法都是说,未初始化的全局变量,编译器编译时将其认为是一个 COMMON 符号,认为在其他的 compile unit 中也可能会存在新的定义,并将 COMMON 符号认为是弱符号。也就是说,如果在 b.c 中申明了
double a;那么最后连接器在链接的时候,就会认为 a 的类型是double 类型,同时将 a 保存到 .bss 段中。也就是说 COMMON 类型的符号,只有在中间编译阶段才会存在,最终链接成可执行文件时,都是在 .bss 段。NOTE:经过测试发现,在现代高版本的 gcc 编译器中,,如果在 b.c 中申明
double a;编译器在编译 b.c 时就直接抛出符号重定义的错误,但是同类型的申明,也就是在 b.c 中申明int a;是合法的COMMON 符号仍然是弱符号,但是规则是允许多个COMMON符号的申明,限制就是同类型的变量,如果是初始化的全局变量,就是强符合,这种就会直接抛出重复定义的错误。
在编译时,加上 -fno-common 选项,就不会有 COMMON 符号生成了,类似上面的变量 a,就直接是在 .bss 段中。
new operator 以及 operator new 的关系
参考 Scott Meyers 的 《More Effective C++》
参考下面这段代码
string *ps = new string("Memory Management");
这里使用的就是 new operator,在 c++ 文档中,也称作 new expression。这个操作符是由语言内建的,类似与 sizeof,不能改变其意义。
这段代码包含了两个意思,
- 分配足够的内存,用来防止 string 类型的对象
- 调用 string 类型的构造函数 constructure,为刚才分配的内存对象进行初始化,设定其值为 “Memory Management”
new operator 或者 new expression 总是同时做这两件事情,不能改变其行为,但是,我们可以改变的,就是申请内存的行为,而这就是 operator new 函数。
new operator 是一个与 sizeof 类似的操作符,而 operator new 是一个函数
operator new 是一个弱符号,我们可以对其进行重载,改变其行为。
还是上面那段代码,用下面这段来解释就是
void *memory = operator new(sizeof(string));
// call string::string("Memory Management") on *memory;
string *ps = static_cast<string *>(memory);
这样,通过重写 operator new ,就能达到添加额外辅助信息的目的了。
bpf tools
在 bcc 软件包中 ,有一个专门用来检测内存泄漏的工具,叫做 memleak。这个工具可以跟踪系统或者指定进程的内存分配,释放请求,然后定期输出一个未释放内存和相应调用栈的汇总情况,通常默认是5秒。还是以上面那个内存泄漏程序为例子,使用 memleak 来检测一下
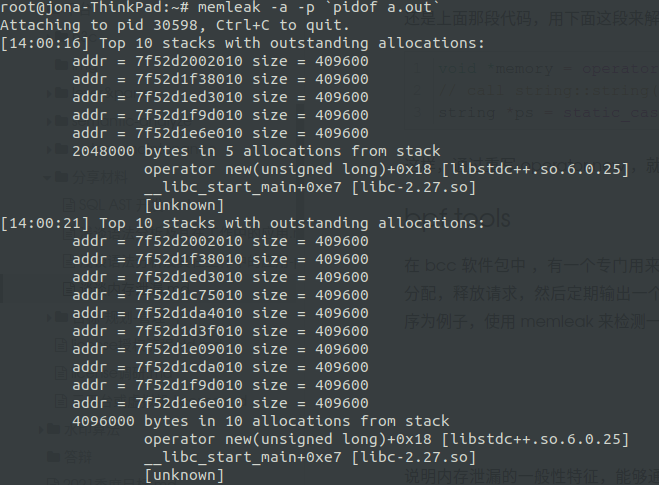
直接打印出了跟踪的函数调用栈和内存泄漏发生的地址。
bcc tools 是 linux 动态追踪工具集,地址是 https://github.com/iovisor/bcc。动态追踪技术通常是基于操作系统内核来实现的。通过探针这种机制,对正在运行的进程的状态信息进行查询和汇总,进而分析当前进程可能存在的问题或者性能瓶颈等。
如果安装 bcc tools,不要使用远程仓库源中已经打包好的二进制安装包,那么安装包比较老旧没有更新,安装上大概率是不能正常使用的。安装方法使用官网提供的源码安装的方式。里面有很多的工具集可以使用。
内存泄漏的简单思考
当然,除了上面说到的内存泄漏检测的方法之外,还有一些其他的工具可以用来进行内存泄漏问题的检查,比如
-
mtrace
-
memwatch
-
mpatrol
-
dmalloc
-
dbgmem
-
Electric Fence
那针对泄漏的内存,是否有一些共性可以观察呢。一般来说,我们可能发生的内存泄漏问题,是在代码出来过程中不小心引起的,没有正确的释放掉申请的动态堆内存。这部分释放出来的内存,都是在程序的一个或者几个特定的地方泄漏的,而且泄漏的内存大小应该都是类似的,甚至可能存储的数据都是大同小异。也就是说,泄漏的内存可能具有一下几个特征:
- 内存的内容不会再改变, 因为没有进程能访问到这块内存。
- 堆中的内存对象,可能会残留使用过的全局变量, 函数名,字符串,指针,特定数值(垃圾满地)。
- 内存中充斥着大量内容相似(相等)的对象。
基于以上三个特征,我们能不能直接从进程的堆内存空间中去发现一些端倪呢???我现在也不知道 :cry:
那如何查看进程的堆空间呢,我们可以效仿 gdb 的方式,使用 ptrace 这个系统调用,attach 到对应的进程上面,然后通过 /proc/maps 和 /proc/mem 两个接口查看进程的堆空间。
gdb 的原理
参考 gdb 底层调试原理
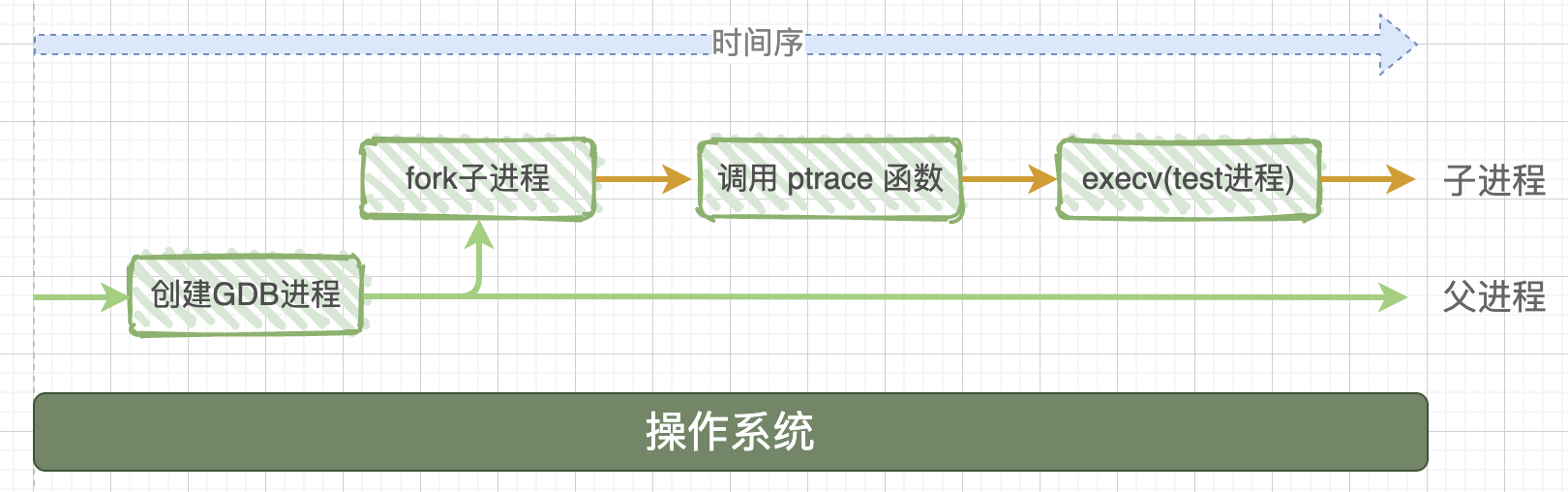
当我们在终端窗口上执行 gdb ./test 的时候,在操作系统里发生了很多复杂的事情:
系统首先会启动 gdb 进程,这个进程会调用系统函数 fork() 来创建一个子进程,这个子进程做两件事情:
- 调用系统函数
ptrace(PTRACE_TRACEME,[其他参数]); - 通过 execc 来加载、执行可执行程序 test,那么 test 程序就在这个子进程中开始执行了。
图片来自网络
而这一切,就是因为系统调用 ptrace,才让 gdb 有了这么强大的功能
#include <sys/ptrace.h>
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
ptrace系统函数是Linux内核提供的一个用于进程跟踪的系统调用,通过它,一个进程(gdb)可以读写另外一个进程(test)的指令空间、数据空间、堆栈和寄存器的值。而且gdb进程接管了test进程的所有信号,也就是说系统向test进程发送的所有信号,都被gdb进程接收到,这样一来,test进程的执行就被gdb控制了,从而达到调试的目的。
上面被调试的程序test是从头开始执行的,是否可以用gdb来调试一个已经处于执行中的服务进程呢? 当然可以,这就是我们经常使用到的 gdb -p 的用法。而这也就涉及到 ptrace 系统函数的第一个参数了,这个参数是一个枚举类型的值,其中重要的是2个:PTRACE_TRACEME 和 PTRACE_ATTACH。
在上面的讲解中,子进程在调用ptrace系统函数时使用的参数是 PTRACE_TRACEME,是子进程调用ptrace,相当于子进程对操作系统说:gdb进程是我的爸爸,以后你有任何想发给我的信号,请直接发给gdb进程吧!
如果想对一个已经执行的进程B进行调试,那么就要在gdb这个父进程中调用 ptrace(PTRACE_ATTACH,[其他参数]),此时,gdb进程会attach(绑定)到已经执行的进程B,gdb把进程B收养成为自己的子进程,而子进程B的行为等同于它进行了一次 PTRACE_TRACEME 操作。此时gdb进程会发送 SIGSTO 信号给子进程B,子进程B接收到 SIGSTOP 信号后,就会暂停执行进入 TASK_STOPED 状态,表示自己准备好被调试了。
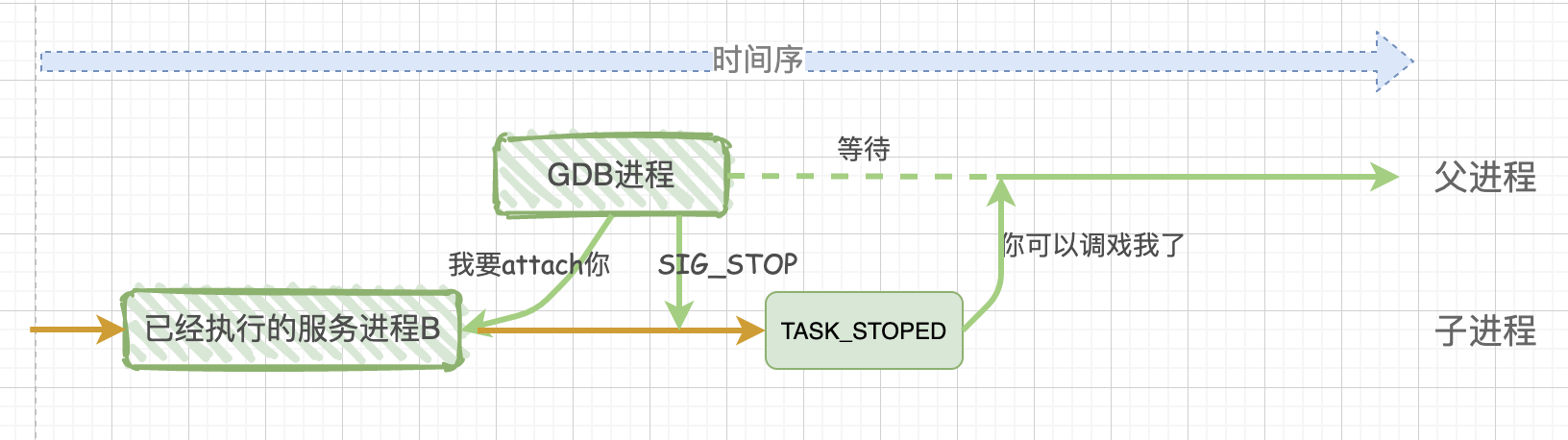
图片来自网络
所以,不论是调试一个新程序,还是调试一个已经处于执行中状态的服务程序,通过ptrace系统调用,最终的结果都是:gdb程序是父进程,被调试程序是子进程,子进程的所有信号都被父进程gdb来接管,并且父进程gdb可查看、修改子进程的内部信息,包括:堆栈、寄存器等。
ptrace 系统调用
- 用
PTRACE_ATTACH或者PTRACE_TRACEME建立进程间的跟踪关系。 PTRACE_PEEKTEXT,PTRACE_PEEKDATA,PTRACE_PEEKUSR等读取子进程内存/寄存器中保留的值。PTRACE_POKETEXT,PTRACE_POKEDATA,PTRACE_POKEUSR等把值写入到被跟踪进程的内存/寄存器中。- 用
PTRACE_CONT,PTRACE_SYSCALL,PTRACE_SINGLESTEP控制被跟踪进程以何种方式继续运行。 PTRACE_DETACH,PTRACE_KILL脱离进程间的跟踪关系。
实操
看下面这个程序
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <malloc.h>
/**
* main - uses strdup to create a new string, loops forever-ever
*
* Return: EXIT_FAILURE if malloc failed. Other never returns
*/
int main(void)
{
char *s;
unsigned long int i;
s = strdup("test_memory");
if (s == NULL)
{
fprintf(stderr, "Can't allocate mem with malloc\n");
return (EXIT_FAILURE);
}
i = 0;
while (s)
{
s = strdup("test_memory");
printf("[%lu] %s (%p)\n", i, s, (void *)s);
/// char* p = malloc(sizeof(char) * 6);
sleep(2);
i++;
}
return (EXIT_SUCCESS);
}
strdup 返回一个 malloc 申请的指针 s,并存储了 test_memory 字符串的值,这个指针是需要通过 free 进行释放的。但是上面这个程序没有进行释放,程序不断通过 strdup 申请内存空间,s 指针每次都被新的指针覆盖,原有的空间就再也访问不到了。这样就造成内存在不断的泄漏。
执行结果如下
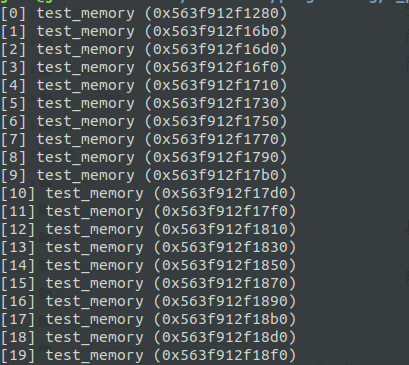
我们使用 ptrace 的方式,来查看这个进程的堆内存空间
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <sys/ptrace.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <string.h>
void dump_memory_region(FILE* pMemFile, unsigned long start_address, long length)
{
unsigned long address;
int pageLength = 4096;
unsigned char page[pageLength];
fseeko(pMemFile, start_address, SEEK_SET);
for (address=start_address; address < start_address + length; address += pageLength)
{
fread(&page, 1, pageLength, pMemFile);
fwrite(&page, 1, pageLength, stdout);
}
}
int main(int argc, char **argv) {
//long ptraceResult = ptrace(PTRACE_ATTACH, child, NULL, NULL);
int child = atoi(argv[1]);
long ptraceResult = ptrace(PTRACE_ATTACH, child, NULL, NULL);
if (ptraceResult < 0)
{
printf("Unable to attach to the pid specified\n");
return 0;
}
char mapsFilename[1024];
sprintf(mapsFilename, "/proc/%d/maps", child);
FILE* pMapsFile = fopen(mapsFilename, "r");
char memFilename[1024];
sprintf(memFilename, "/proc/%d/mem", child);
FILE* pMemFile = fopen(memFilename, "rw");
char line[256];
while (fgets(line, 256, pMapsFile) != NULL)
{
if (strstr(line, "[heap]") == NULL) continue;
unsigned long start_address;
unsigned long end_address;
sscanf(line, "%12lx-%12lx\n", &start_address, &end_address);
dump_memory_region(pMemFile, start_address, end_address - start_address);
}
fclose(pMapsFile);
fclose(pMemFile);
sleep(2); /// 此处sleep 2 秒方便观察 attach 到的进程,被 attach 的进程处于 SIGSTP 状态,知道后面的 CONT 和 DETACH 调用后才恢复
ptrace(PTRACE_CONT, child, NULL, NULL);
ptrace(PTRACE_DETACH, child, NULL, NULL);
return 0;
}
通过 /proc/[pid]/maps 文件,读取 heap 对空间的虚拟地址空间起始地址,根据起始地址在 /proc/[pid]/mem 文件中,读取对应位置的内存数据。
NOTE: 执行上面读取进程堆空间的程序,必须使用 root 权限,否则会 attach 不成功

我们发现,整个堆空间中都是 test_memory 这样的字符串。而这部分空间都是泄漏的内存。
这只是提供了一整思路,可以用来帮助我们思考和定位内存泄漏的现象。但是如何从堆内存这一大堆数据中去分析出实际的泄漏点,是一个尚需发掘的问题。
这里借鉴了一篇定位 linux 内核内存泄露问题的文章 AK47所向披靡,内存泄漏一网打尽